Introduction
Phylogenetic diversity was originally conceived as a metric to inform conservation, and spatial conservation planning is a core application of spatial phylogenetics. Spatial conservation planning involves identifying priority locations for actions like the creation of new protected areas.
There are a diversity of sophisticated tools available for conservation planning. This package performs conservation prioritization using a stepwise algorithm that selects an ordered ranking of priority sites for the creation of new protected areas. Unlike many other algorithms, this method can utilize quantitative community data (rather than just binary presence-absence data), and it can utilize quantitative data on the relative degree of protection offered by different types of protected area (rather than just binary protected-unprotected data).
Prioritization is handled by the function
ps_prioritize(). A site’s priority ranking is a function
of:
- its current protection level
- the occurrence quantities for all lineages present in the site, including terminal taxa and larger clades
- the evolutionary branch lengths of these lineages on the phylogeny, which represent their unique evolutionary heritage
- the impact that protecting the site would have on these lineages’ range-wide protection levels
- the compositional complementarity between the site, other high-priority sites, and existing protected areas
- the relative cost of protecting the site
- lambda, a free parameter determining the shape of the conservation benefit function (see below)
This vignette covers basic conservation optimization, probabilistic prioritization, and further detail about conservation benefit functions.
Basic optimization
Let’s use the example data set for California mosses to perform a conservation optimization that ranks every grid cell across the state.
At every step of the iterative ps_prioritize()
algorithm, the marginal value of fully protecting each individual site
is calculated. Under a basic optimization
(method = "optimal"), the site with the highest marginal
value is marked as protected, marginal values are re-calculated, and
this process is repeated until all sites (or max_iter
sites) are protected. Sites selected earlier in the process are
considered higher priority.
In addition to the required spatial phylogenetic data set, there are
two other optional data inputs that one might want to provide. The first
is init, the location and effectiveness of existing
protected areas. This can be binary data representing protected versus
unprotected sites, or continuous data with values between 0 and 1
representing the degree of protection (for example, perhaps because a
given spatial unit is only partially covered by protected land, or
because land management in sites like national forests is only partly
oriented toward biodiversity protection). During the conservation
optimization, the protection level for newly protected sites is raised
to 1 (or to an alternative level specified by the parameter
level), with greater benefit resulting from sites with
lower initial values.
The second optional variable is cost, representing the
relative cost of protecting different sites across the study area. Sites
with high benefit-to-cost ratios are prioritized. For this example,
we’ll just specify an arbitrary initial protection gradient from north
to south and a cost gradient from east to west, though of course a real
analysis would require actual data. For simplicity we’ll provide these
as vectors (with length equal to ps$n_sites, the total
number of grid cells including unoccupied ones), but we could also
provide raster layers matching the spatial element of our
data set.
First let’s load the libraries we’ll need, and initialize a
phylospatial data set using the example data for California
mosses. (See vignette("phylospatial-data") for details on
constructing phylospatial objects.) We’ll also create a
variable called init specifying our (arbitrary) initial
conservation values, and cost defining some hypothetical
land cost data.
library(phylospatial); library(tmap); library(magrittr)
ps <- moss()
init <- seq(1, 0, length.out = ps$n_sites)
cost <- runif(ps$n_sites, 10, 1000)Now we’ll pass those inputs to ps_prioritize(). Plotting
the result, the highest-priority sites are those with low rank values,
shown in yellow.
priority <- ps_prioritize(ps, init = init, cost = cost)
tm_shape(priority) +
tm_raster(col.scale = tm_scale_continuous_log(values = "-inferno")) +
tm_layout(legend.outside = TRUE)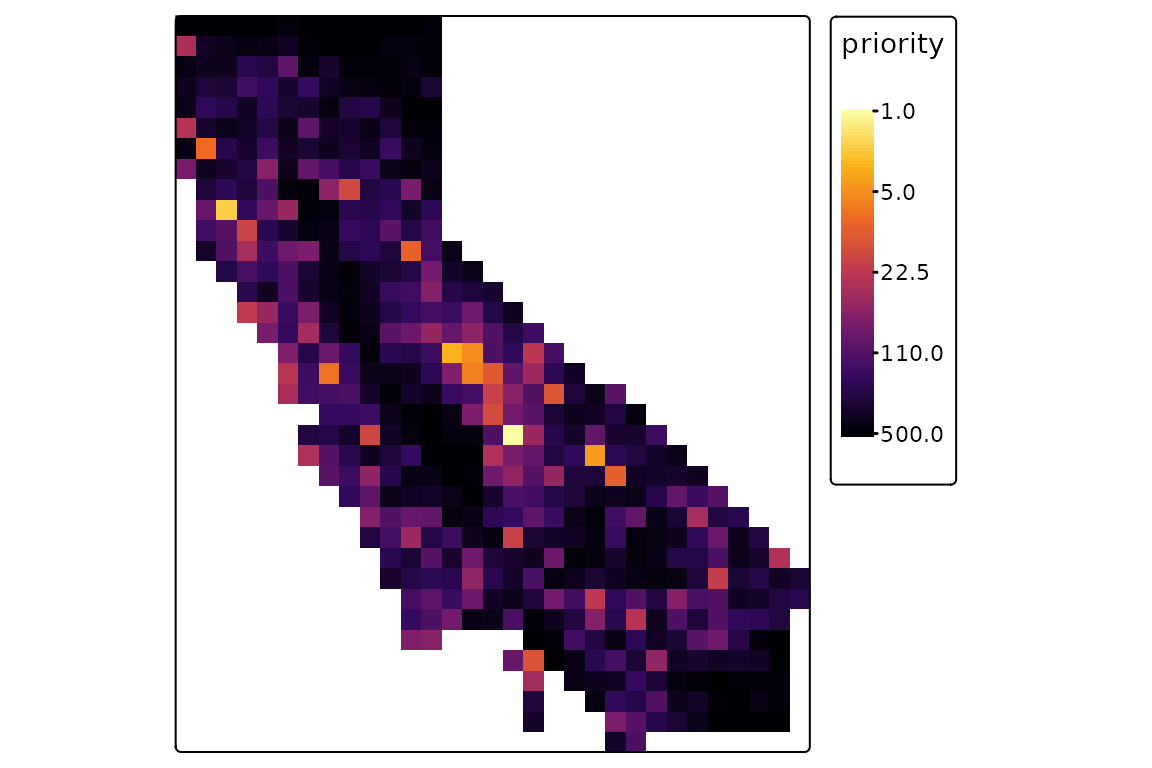
Probabilistic prioritization
The routine shown above gives the optimal priority ranking, based on the assumption that sites are selected in the optimal order. This is an informative result and a relatively lightweight computation, but it has limitations. First, assuming optimal behavior may be unrealistic. And second, since the algorithm values complementarity (i.e. protection of sites that have distinct, non-redundant biotic communities), sites with high conservation value that could be attractive real-world priorities can be entirely overlooked if they are compositionally similar to sites that were already selected because they have slightly higher value.
Probabilistic prioritization, activated with
method = "probable", addresses these issues. At each
iteration, instead of protecting the site with the highest marginal
value as done in the "optimal" method, this approach
protects a random site, selected with a probability that is a function
of the site’s marginal value. The trade-off is that individual runs of
the algorithm can be highly variable, so the algorithm needs to be run
many times, and prioritization rankings summarized across these repeated
runs. When using the probabilistic method, ps_prioritize()
returns summary statistics for each site including its average priority
rank across reps, various quantiles of its rank distribution, and the
proportion of reps in which a site was among the top-ranked sites.
Running a large number of n_reps can substantially
increase computation times, but there are two ways to help mitigate run
times. First, you can use parallel processing by increasing
n_cores above the default of 1. Second, you can set
max_iter to a relatively small number, which stops the
algorithm after this number of sites have been added. For example, if
your data set has 1000 sites, setting max_iter = 10 can
reduce run times by almost two orders of magnitude. While you won’t get
a full rank prioritization of all sites from any individual rep, you
will get the proportion of reps in which a site is in the top 10, which
is arguably even more useful.
Let’s demonstrate that here; we’ll run 2500 reps, though more might be better for a real analysis:
priority <- ps_prioritize(ps, init = init, cost = cost, n_reps = 2500,
method = "prob", max_iter = 10)
tm_shape(priority$top10) +
tm_raster(col.scale = tm_scale_continuous(values = "inferno"),
col.legend = tm_legend(title = "proporiton of runs\nin which site was\ntop-10 priority")) +
tm_layout(legend.outside = TRUE)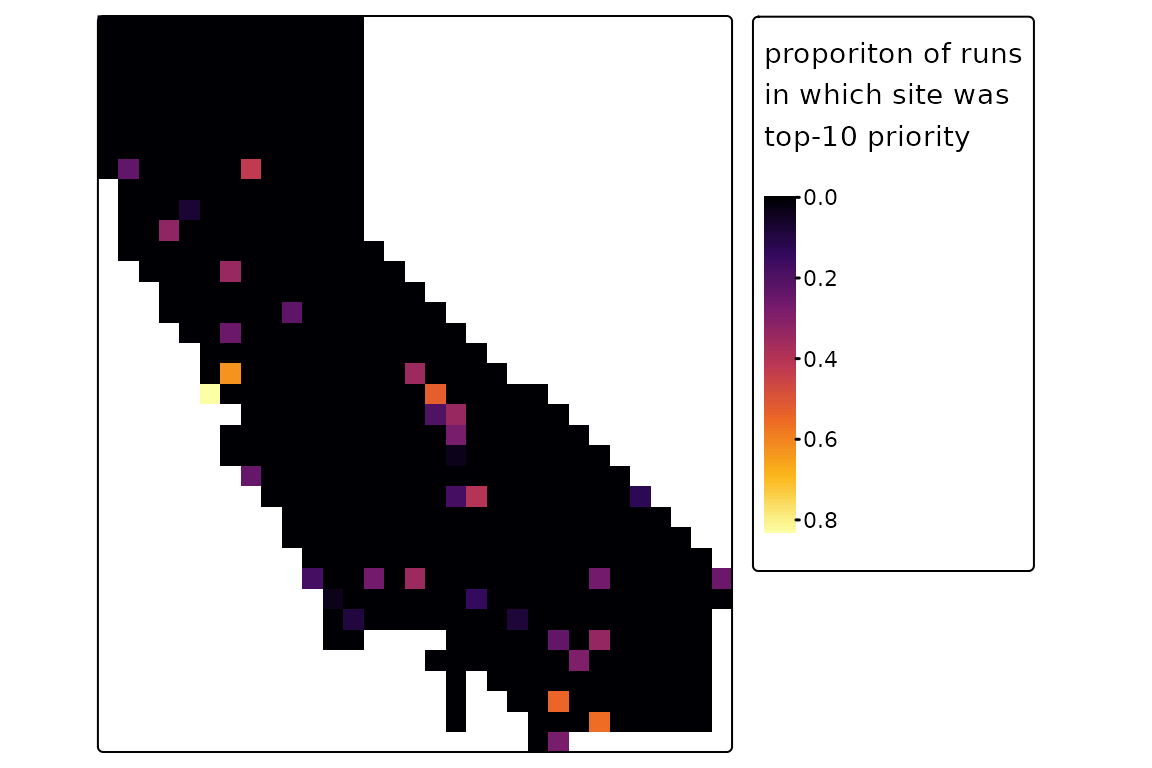
Conservation benefit functions
In the examples above, we used the default value for the
lambda parameter. lambda controls the relative
priority placed on protecting initial populations of every taxon versus
more populations of more phylogenetically distinct taxa. More precisely,
it determines the shape of the benefit() function that
converts the proportion of a taxon’s range that is protected into a
conservation benefit measure that is used in calculating the marginal
value of sites during prioritization.
We can use the function plot_lambda() to compare the
shapes of benefit functions under different lambda values:
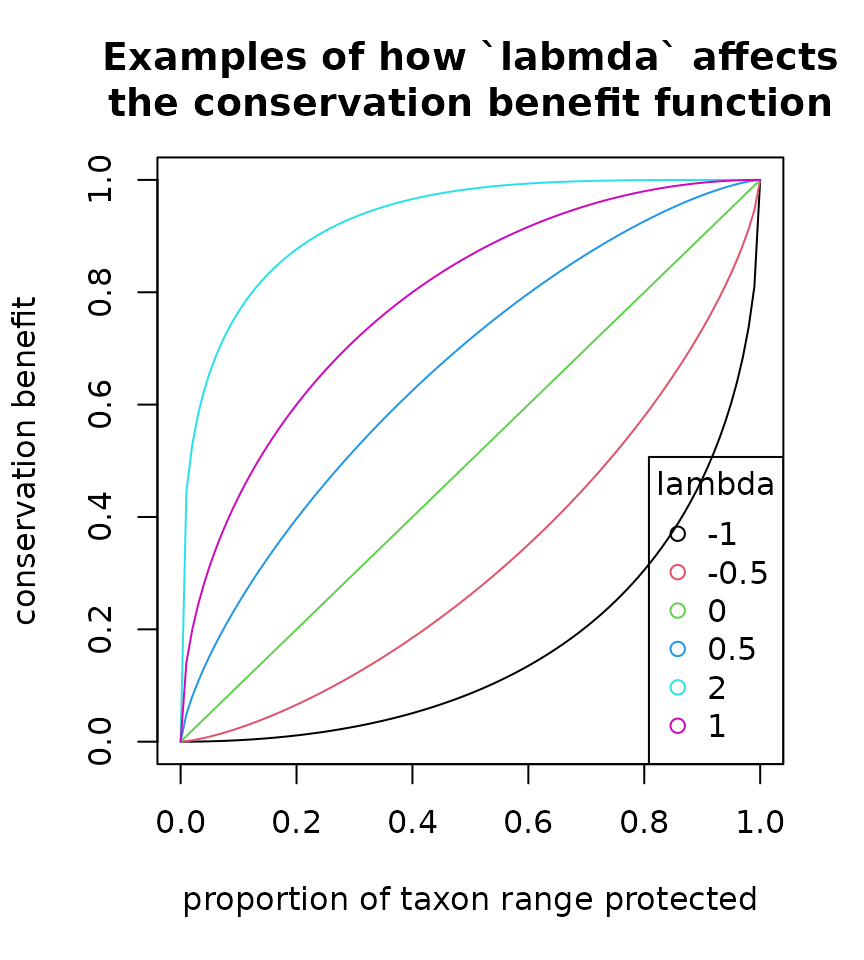 A value of
A value of lambda = 0 places equal marginal value on
protecting additional populations of a taxon regardless of how much of
its range is already protected. The default of lambda = 1
places higher priority on protecting populations of unprotected taxa,
but still places some value on increasing the protection of taxa that
are already reasonably well protected. Increasing the value to
lambda = 2 strongly emphasizes protecting the first few
percent of a taxon’s range, and places virtually no value on increasing
protection beyond 50%. Lambda can also be negative, which places greater
value on “finishing the job” of protecting the entire range of a lineage
than on “starting the job” of protection a portion of its range;
negative values are not likely to be useful in most practical
applications.
Deciding which value to use is a subjective choice, and you should consider what makes the most sense for your particular use case. It can also be useful to compare different values to understand how sensitive your results may be to this choice.